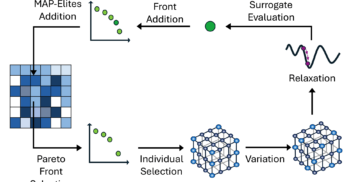


Provides updates on BioNTech’s strategy to scale and deploy AI-capabilities across the immunotherapy pipeline Highlights InstaDeep’s new near exa...

BioNTech Highlights AI Capabilities and R&D Use Cases at Ina...
on Oct 01, 2024 | 01:00pm
InstaDeep delivers AI-powered decision-making systems for the Enterprise. With expertise in both machine intelligence research and concrete business deployments, we provide a competitive advantage to our customers in an AI-first world.
Learn MoreOur latest updates from across our channels
on Oct 01, 2024 | 01:00pm
Provides updates on BioNTech’s strategy to scale and deploy AI-capabilities across the immunotherapy pipeline Highlights InstaDeep’s new near exa...

on Sep 11, 2024 | 05:56pm
Amid the vibrant energy of the Deep Learning Indaba 2024, InstaDeep proudly reinforced its commitment to advancing AI innovation across Africa by supporting a new edition of this...

on | 03:50pm
San Francisco, CA – 12th September 2024 – InstaDeep, in collaboration with Google Cloud, unveiled today the advanced version of its AI-powered Printed Circuit Board (PCB) desi...

on Jul 24, 2024 | 12:07pm
InstaDeep's goal of using AI to enhance speed and efficiency in the PCB design landscape is moving forward at pace. Our team recently showcased DeepPCB, our advanced cloud-based d...

on Jul 18, 2024 | 02:04pm
The International Conference on Machine Learning (ICML) stands as one of the premier gatherings, bringing together the brightest minds from academia, industry, and research instit...

on Jun 18, 2024 | 01:30pm
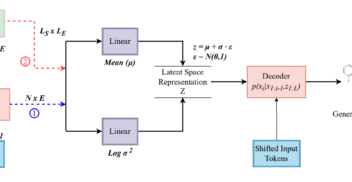
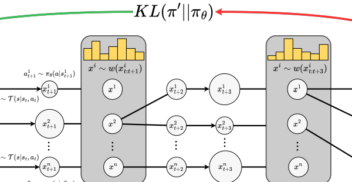
This collaboration further strengthens the Syngenta Seeds R&D engine for speed, precision, and power, accelerating trait advancement.Large Language Models (LLMs) aim to reduce...

on May 07, 2024 | 10:04am
InstaDeep maintains its strong commitment to open research with six papers accepted for presentation at the 2024 ICLR conference being held in Vienna this week. The accepted pa...

on Apr 30, 2024 | 03:41pm
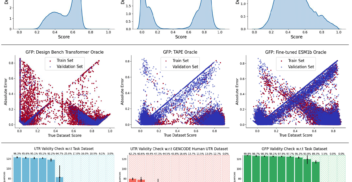
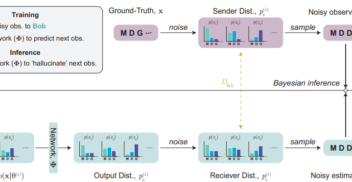
The human genome, containing the entirety of our genetic blueprint, holds the keys to understand the intricate workings of our cells and bodies. How our cells respond to signals,...

on Apr 04, 2024 | 01:16pm
Divanisha Patel was working for a bank when the possibilities AI holds for positive change caught her imagination. Divanisha decided to make the jump from finance to AI. Now a...

on Mar 26, 2024 | 05:22pm
Can competitive swimming prepare you for the dive into AI? Once a competitive swimmer in national and international competitions for 18 years, Narimane Hennouni brings a c...